CivicLens Devlog
How AI can turn bureaucratic opacity into structured, verifiable civic clarity.
Most government decisions that affect our daily lives are technically public. They’re open for everyone to read, archived, and searchable — but almost impossible to understand.
Council agendas run dozens of pages. Budget documents bury critical changes in dense tables. Public notices describe obligations in language only lawyers can read. The information is there, but clarity isn’t provided for the average person.
That gap is where CivicLens begins.
The Idea Behind CivicLens
CivicLens is a non-partisan AI assistant designed to translate complex public documents into clear, structured, plain-language insight — without losing accuracy, and without inserting opinions or judgment into the core information.
Upload a council agenda. Upload a municipal ordinance. Upload a public notice. Within moments, CivicLens tells you:
- What changed
- Who is affected
- What actions or deadlines matter
- Where exactly that information appears in the source document
Every key statement links back to a verifiable citation from your uploaded document. No summaries floating in abstraction. No “trust the AI.” Just structured clarity anchored to the original text.
The goal isn’t persuasion. It’s understanding.
A deliberate choice in CivicLens’s design is to separate extraction from interpretation. The system is not asked to evaluate whether a decision is good or bad, fair or unfair. It is asked to find, structure, and cite. This architectural constraint is what keeps the tool useful across political contexts — not a claim of perfect objectivity, which no AI system can honestly make, but a structural commitment to staying close to the source.
Why This Problem Matters
Transparency is often mistaken for accessibility. If a 70-page PDF is online, the political system assumes the public is informed. But in reality, the time, expertise, and patience required to decode those documents creates a silent barrier — not only for citizens whose mother tongue is not the language of the document, but for many others too.
Exemplary implications of not understanding bureaucratic language:
- Citizens miss deadlines — facing fines, legal consequences, or permanent loss of entitlements simply because the language of the notice was inaccessible
- Journalists lose hours scanning for relevance — missing the story entirely while those in power count on complexity to avoid scrutiny
- Community groups discover regulatory changes too late — unable to organize, protest, or challenge decisions that have already been quietly passed into law
CivicLens transforms “public but unreadable” into something actionable. It lowers the entry barrier to civic participation without altering the substance of the information itself.
CivicLens is built for anyone who has ever opened a government document and felt lost — from the first-generation citizen navigating a bureaucratic system in a second language, to the seasoned journalist racing a deadline, to the local activist trying to hold institutions accountable. If public information exists, it should be truly accessible to everyone, not just those with the time, training, or privilege to decode it.
Building CivicLens: From Upload to Insight
The system behind CivicLens is intentionally simple, but carefully structured.
Document Ingestion
When a user uploads a document, the pipeline begins with a pre-signed upload URL and a newly generated document ID. The file is stored in a raw S3 bucket — untouched and preserved exactly as received, so the original document remains accessible for every subsequent analysis.
Text Extraction
Once the file lands in the S3 raw bucket, an event automatically triggers a Lambda function that extracts the document’s text and stores it as a clean, processable plain-text artifact — ready for the analysis pipeline.
State Machine
Every stage of the document’s lifecycle is tracked in a lightweight meta.json file. No traditional database backend is required. The processing state, error codes, and timestamps are all stored there, implementing a small but reliable state machine. If anything fails, the system transitions to ERROR and the error message and code are saved in the meta file.
Architecture Overview
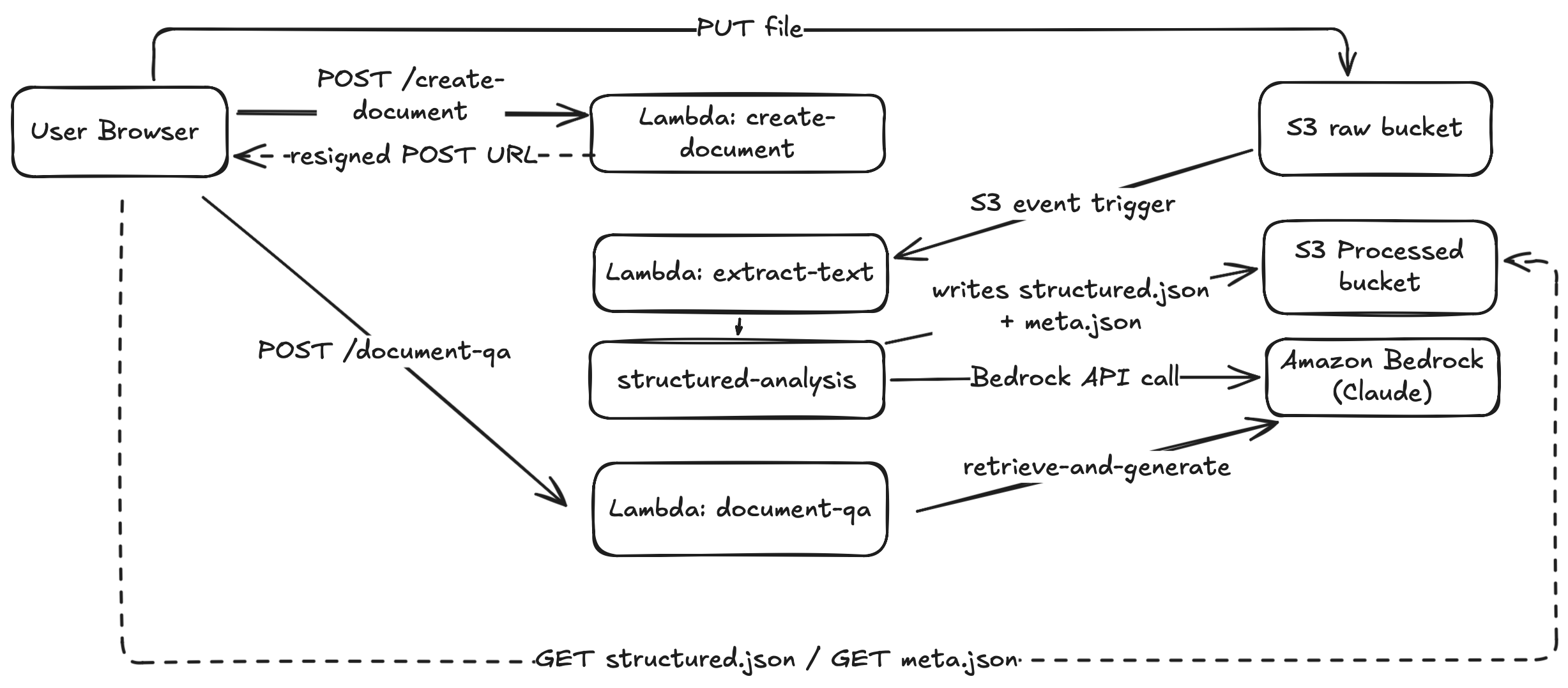
Structured Analysis
Once the text is extracted, a second Lambda function takes over. Using Amazon Bedrock with Anthropic’s Claude Opus 4.5, CivicLens performs deterministic extraction guided by a strict JSON schema. The model is not asked to “summarize creatively.” It is required to:
- Extract key decisions
- Identify affected groups
- Detect deadlines
- Provide direct evidence quotes
- Output structured JSON only
After the model’s output is received, it is validated against the required schema to ensure all required fields are present and correctly formatted. If validation fails, a backup prompt is triggered to ensure a correctly structured response.
It’s important to note that structural validation alone cannot guarantee semantic correctness — the model may produce output that is well-formed but does not accurately reflect the content of the original document. This is an inherent limitation of any LLM-based extraction system and a known area for future improvement.
The final result is a structured.json file — a verifiable representation of the document’s core information. Throughout the whole process, the UI polls the meta.json file and displays the current state. Once the state switches to DONE, the generated insights appear in a structured, human-readable layout on the frontend.
Grounded Q&A — Minimizing Hallucination Risk
Beyond structured summaries, CivicLens includes an optional Q&A layer. When a user asks a question, a dedicated Lambda function calls Amazon Bedrock’s Knowledge Base using a retrieve-and-generate approach.
The answer is grounded in the processed document content, and citations are returned alongside every response. This dramatically reduces hallucination risk. Instead of inventing context, the model retrieves relevant passages and generates responses tied directly to them.
Answers are stored under a timestamped path, creating a traceable record of every interaction with a given document.
Design Decisions That Matter
Several architectural choices shaped CivicLens — each one driven by the same question: what does a civic tool need to earn and keep the trust of its users?
- Event-driven serverless design using S3 and Lambda keeps the infrastructure lightweight, scalable, and auditable — every step of the pipeline is a discrete, inspectable function rather than a monolithic black box
- Original files are never overwritten. The raw document lives in a separate bucket, untouched, while all derived artifacts live in a distinct namespace. The source of truth is always preserved
- Lightweight state tracking via
meta.jsoninstead of a traditional database keeps the system simple - Schema-enforced extraction means the model is never asked to summarize freely — it receives a strict output contract it must follow, dramatically improving consistency
- Every key statement must be tied to a direct quote from the source document. Plausible is not the same as verifiable, and in civic contexts, verifiability is everything
Built with Kiro — and Within Free Tier
CivicLens was developed using Kiro, AWS’s agentic IDE, which proved particularly valuable for designing and iterating on the frontend UI, and running stress tests against the Lambda pipeline to identify bottlenecks before they became real problems.
The entire infrastructure — S3, Lambda, API Gateway, and Amazon Bedrock — runs within AWS Free Tier limits, meaning the cost of running CivicLens at a reasonable usage level is effectively zero. This was not an afterthought but a deliberate architectural constraint from day one, proving that civic technology does not have to be expensive to be reliable.
See It in Action
The best way to understand CivicLens is not to read about it - but to watch it work. The demo below shows a real German government document being processed from a raw PDF into structured, citable English insights. No staging, no hand-picked input - just the pipeline doing what it was built to do. The original document, raw output, and screenshots are all available in the GitHub repository linked below.
If you want to dive deeper, the landing page gives a full product overview, and the GitHub repository contains the complete AWS Lambda pipeline, architecture diagrams, and all the code — open for anyone to read, inspect, and build on (MIT license).
live landing page · GitHub repo
What I Learned
Building CivicLens reshaped how I think about AI systems in civic contexts.
- Prompting alone is not enough. Reliability comes from constraint. Strict schemas, required evidence, and deterministic formatting dramatically improve consistency
- Citations change everything. A summary without grounding feels speculative. A summary with traceable quotes feels credible
- Serverless architecture is ideal for early-stage civic technology. Using S3, Lambda, API Gateway, Amplify, and Bedrock made it possible to build a complete pipeline within Free Tier limits — while remaining fully scalable
The Bigger Vision
CivicLens doesn’t aim to replace institutions or reinterpret policy. It aims to make public information truly public.
If democratic participation depends on understanding decisions, then clarity is infrastructure. CivicLens turns bureaucratic opacity into structured visibility — grounded, neutral, and verifiable.
And that’s where better civic engagement begins.